本文记录我在读论文《Deep Residual Learning For Image Recognition》时的一些笔记与思考。在读的过程中有一些名词很难理解,经过上下文推敲可以大致猜出其含义,推荐自己读完了之后再观看李沐的ResNet论文讲解视频,可以有更深刻的理解。
研究背景
深度卷积神经网络在图像分类任务中达到一系列的突破。深度网络很自然地将不同层的特征融合起来,形成一个端到端的多层网络风格,而且随着层数的增加,所提取的特征也更加丰富。这随即就引发思考:学习更好的网络就像堆叠更多的层一样简单吗?
事实是,随着网络的层数的叠加,我们会遇到梯度消失和梯度爆炸 问题,而这个问题也会阻碍模型的收敛。然而规范化初始化(normalized initialization)和 intermediate normalization layers很好的缓解了这个问题,前者指的是在初始化权重的时候注意不将值设置太大也不要特别小,后者指的是在网络中间加一些normalization,比如BN: batch normalization可以校验每个层之间的输出以及梯度的均值和方差,避免有些层特别大,有些层特别小。这就使得包含很多层的网络开始可以基于随机梯度下降(SGD)的优化器进行反向传播收敛了。但是,随着网络层数的加深,精确度开始饱和,然后急剧衰减。作者将这种现象称为退化问题(degradation problem)。而且这种退化问题不是由于模型的层数变深、模型的参数变多而过拟合导致的,给一个网络添加更多的层会导致更高的训练误差,这一结论在作者的实验中得到了证实,如下图所示(图来自论文原文):
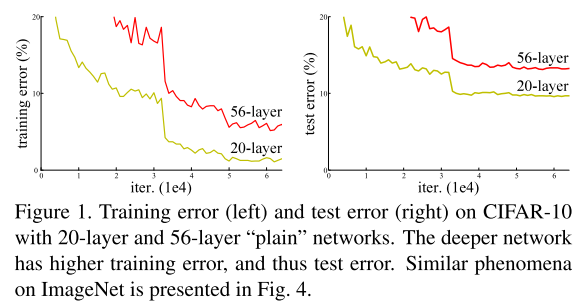
plain指的是没有使用残差结构的网络。假设有一个浅层的网络,已经优化的比较好了,如果为其增加更多的网络层,作者认为结果不应该变得更差,大不了也只是和没有添加这些层的结果一样,即直接跳过这些层输出结果,这个映射过程称为identity mapping。但是我们目前的优化方法做不到。所以作者希望构造一个这样的结构(identity mapping),使得更深的结构不会比浅层结构表现更差。
核心思想
为了解决上述退化问题,作者提出深度残差学习框架 (deep residual learning framework )。作者不是直接提出一种网络层的堆叠方式来直接学习所需要的underlying mapping(可以理解为网络层最终可以实现的函数映射功能),而是构造满足残差映射(residual mapping)的网络层。假设所需要学习的underlying mapping 为,是浅层网络所学习到的内容,然后继续添加若干层残差映射网络层,这些层不按照前几层的学习模式来直接学习,而是学习与之间的残差:
这样一来,我们最终需要学习的可以表示为。这一结构可以使用神经网络前向传播过程中的捷径连接(shortcut connections)来实现,其中,不经过残差映射网络层直接输出的部分就是上面提到的identity mapping,即下图的捷径部分,如下图所示(图来自论文原文):
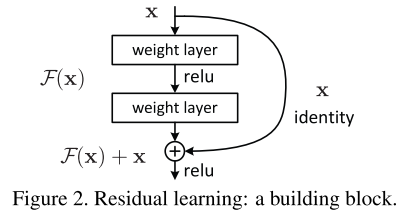
这一结构不会增加任何额外的参数数量以及复杂的运算,一样可以被SGD端到端地训练,且容易实现。在实验中也表明,在较深的神经网络中,文章提出的deep residual nets很容易优化,而随着网络的深度加深,通过简单堆叠若干层的网络('plain' nets)会产生更大的训练误差,本文的新网络却可以学习到更多的内容并提高精度。
进一步细节阐述
深度残差学习(Deep Residual learning)
假设是一些堆叠网络层(不一定是整个网络)需要达到的映射结果(函数),表示这一些堆叠网络层的输入。假设函数可以通过堆叠一系列非线性层来不断逼近,常规的神经网络就是通过不断的堆叠网络层来拟合,但是本文直接拟合的是残差函数,即。
因此一开始我们需要求的函数就变成。这样设计的动机是层数增加反而导致训练误差增加的反直觉现象。因为如果后面的网络层可以起到identity mapping的作用,那么增加网络层数即使不会提高网络的精度,也不至于训练过程模型性能一直降低。模型性能退化的现象表明,多层非线性网络层在拟合identity mapping的过程中有困难。使用残差结构训练,如果identity mapping是最优的,模型可以让多个非线性层的权值趋向于零,以接近identity mapping。作者认为,残差结构应该更容易学习,因为这样的话网络只需要学习和期望值之间的残差,而不是学习一个全新的值。在本文中的残差结构可以使用如下的表达式来表示:
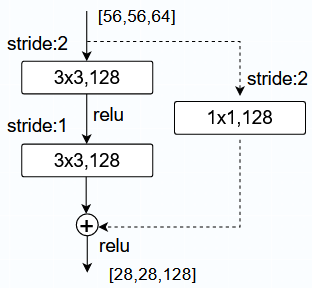
和表示的是所考虑层的输入和输出向量。表示需要学习的残差映射。比如在Fig.2中的残差结构图中,残差映射结构有两层网络层,所以在Fig.2的情况下,,其中表示的是relu函数,为了简化公式,这里将偏置bias省略了。 使用一个捷径连接来表示(见图Fig.2),二者的相加操作指的是两个特征层各个通道对应元素的加法操作(element-wise addition)。如果和的维度不同,可以用一个线性投影矩阵与相乘,使得二者的维度相同:
残差函数的结构很灵活,在本文中提到了两种结构的残差函数:2层和3层,当然更多层数也可以。残差函数中的网络层不仅可以关于全连接层,还可以适用于卷积层,这样可以表示成不同的卷积层。
网络结构
作者称没有使用残差结构的网络为plain nerwork,有残差结构的网络为residual network。基于VGG的设计理念的启发,作者设计一个plain network,卷积层大多使用的是3x3的filters,而且总是保持两条规则:
- 有相同输出特征图大小的层也有相同数量的filters(相同数量的filters会有相同的通道数,这就保证了通道维数相等);
- 如果特征图大小减半,为了保持每层的时间复杂度,filters的数量需要增加一倍。
下采样过程直接使用stride为2的卷积操作,网络的结尾是一个全局平均池化层以及一个1000维度的全连接层加上softmax输出。plain network的结构如下图中间所示,左边是VGG-19的网络结构,右边是34层的residual net的网络结构:
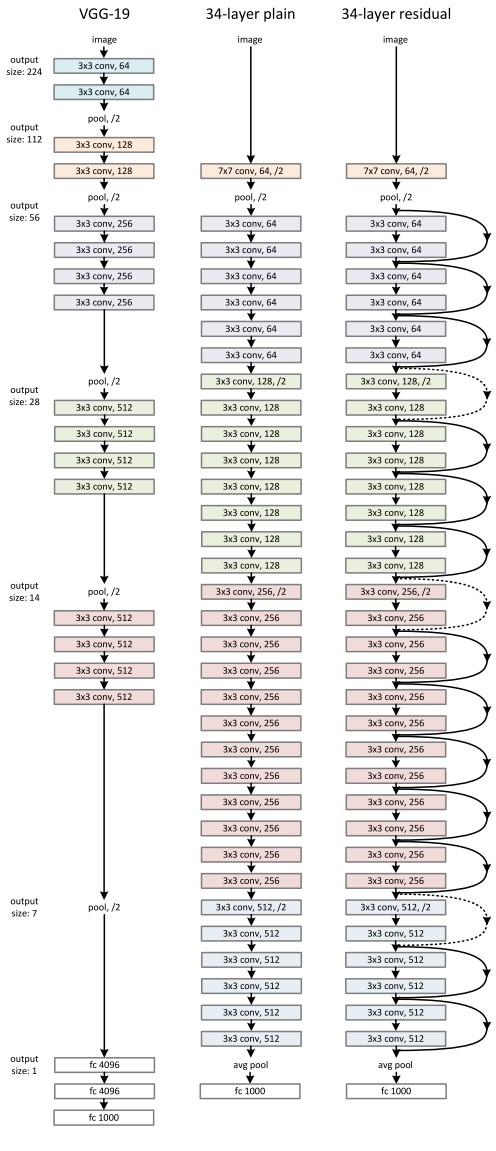
plain network有更少的filters,而且相比于VGG有更低的复杂度。基于上述的plain network,通过添加捷径,将网络转换为一个残差网络。当输入和输出特征矩阵的维度相同时,可以直接使用identity shortcuts(上图网络结构中实线捷径),如下图结构所示(输入残差结构的维度64-d没有发生改变):
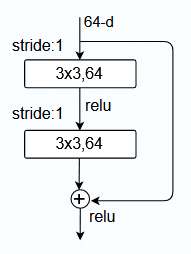
当特征矩阵的通道维度增加的时候(虚线捷径),可以考虑两种处理方法:
option A. 捷径仍然进行identity mapping,如果输入输出维度不相等就填充额外的0(zero-padding)使得二者的维度相等,这个操作不会增加额外的参数;
option B. 使用投影捷径(projection shortcut): 使用线性投影矩阵与相相乘,从而使得通道维度互相匹配,这里使用1x1的卷积层来改变输入特征的通道维度数量。一般情况下,通道数如果变为原来的两倍,那么通常会使用stride=2将长和宽变为原来的一半,如下图结构所示:
实现细节的小tricks
文章中很多实现的小tricks参考了其他论文:
-
尺度增广:在[256,480]范围内对图像的短边进行随机采样,对图像进行缩放。参考:
《Very deep convolutional networks for large-scale image recognition》
-
从图像或者其水平翻转版本中随机采样大小为224x224的裁剪图像,并减去像素均值;使用颜色增强(调一下亮度饱和度等);在测试阶段,为了对比学习,使用标准10-crop testing(在图像中按照某种规则采样10个子图,在每一个子图上做预测,然后将结果取平均。因为训练的时候是随机的,所以测试的时候也可以模拟这个过程,一下子做10次预测也可以降低方差)。参考:
《Imagenet classification with deep convolutional neural networks》
-
在每一个卷积层和激活函数之间使用Batch normalization,而且不使用dropout。参考:
《Batch normalization: Accelerating deep network training by reducing internal covariate shift》
-
初始化权重;为了达到最好的效果,使用全部为卷积层的构造形式,而且在不同的分辨率下的图片进行预测然后取平均,参考如下。并求在多个图像尺度上的平均分数(图像大小被调整,较短的一侧在{224,256,384,480,640})。
《Delving deep into rectifiers: Surpassing human-level performance 》
-
使用优化器为SGD,batch size=256;学习率一开始为0.1,当误差趋于平衡时,除以10(这个也少用,因为需要一直守在旁边,确定何时除10);网络训练的迭代次数为(这种写法少见,因为迭代次数受batch size影响,一般使用的是epoch来衡量);使用的权重衰减为0.0001,动量为0.9。
实验思路与细节
发现问题并尝试现有方法解决
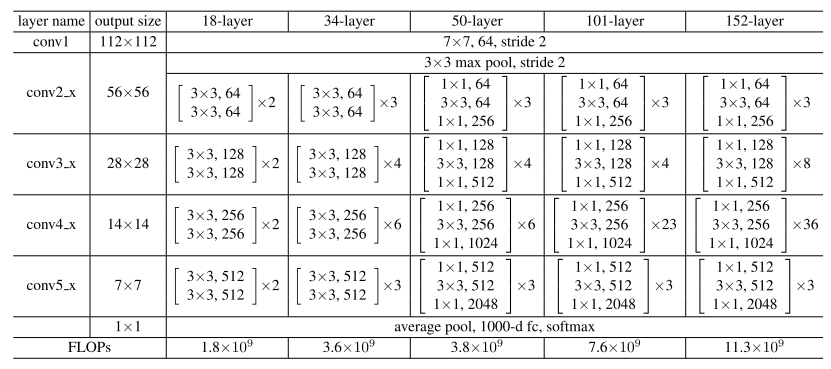
首先按照常规的思路,为了验证网络的深度加深会导致模型性能的降低,作者先训练18层的plain net和34层的plain net。二者的网络结构如下表1所示(表1来自原论文):
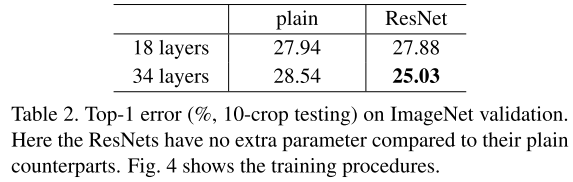
然后作者发现,在验证阶段,34层的验证误差比18层的验证误差高,如下表2所示(表2来自原论文):
为了探究原因,到底是34层网络复杂度太高而导致的过拟合还是其他原因,作者将34层plain net和18层plain net的训练过程和验证过程误差值的变化曲线作出来以便比较,虚线是训练过程,实线是验证过程:
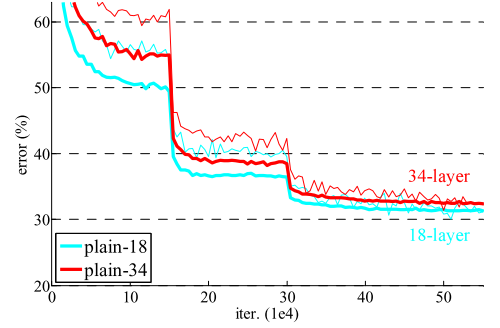
从图中容易发现,整个训练过程34层的plain net误差也比18层的plain net误差高,所以问题不是简单的过拟合,作者推测可能深层plain net收敛速度在以指数级别降低,影响了训练误差的减少。作者尝试通过3倍的迭代次数来重新训练,但是仍然出现退化问题,这就表明这个问题无法通过简单的增加迭代次数来解决。
使用本文提出的新方法解决
使用18层和34层的residual nets(ResNets)来实验。网络的baseline 结构和上述的plain nets结构相同,在plain net结构的基础上添加了捷径连接。
所有捷径使用identity mapping(option A)
如果维数增加就使用零填充(zero-padding),这样相对于相同层数的plain net没有额外的参数量。结合表2和plain nets、ResNets(下图所示,图来自原论文)的实验数据:
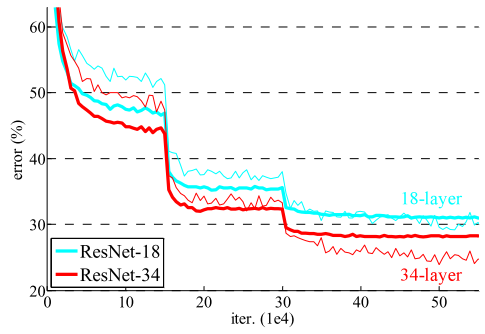
我们发现三个要点:
- 在ResNets中,情况完全相反,训练误差低于测试误差,而且34层的ResNet比18层的ResNet更优。这表明模型性能退化的问题在我们的方法中得到了很好的解决,我们可以通过增加层数来获得更高的精度。
- 从表2的top-1 error中可以看出,34层的ResNet相比于34层的plain net有更低的误差,这得益于ResNet-34更低的训练误差,这个比较的结果验证了ResNet在深度神经网络中的有效性。
- 虽然plain net和ResNet在最终有比较相近的精度,但是ResNet的收敛速度比plain net更快,比如误差50%的时候,plain net-18需要进行大概次迭代,而ResNet-18需要进行大概次迭代。在这种不是特别深的网络的情况下,SGD仍然可以为plain net求出优解,相同情况下,ResNet可以使得优化过程更容易,让网络在早期更快地收敛。
既然提出来的方法可以很好的解决问题,那么接下来继续探究所提出来的几种方法以何种组合方式更优(option A和option B)。
使用projection shortcuts(option B)
为了探究option A 和option B以什么样的组合方式更优,作者进行了三种实验:
A. 使用零填充(zero-padding)来解决维度增加的情况,所有的捷径都是无参数的(和上述的option A所做的实验一样);
B. 使用投影(1x1卷积层)来解决通道数不匹配的情况,这会增加参数的数量,其他的捷径(维度未增加)使用identity mapping;
C. 所有的捷径(不论前后特征图通道数是否相匹配)都使用投影(1x1卷积层)。
实验结果表明,A/B/C都比plain net效果好,其中,B的效果比A略好,C比B效果好,三种实验结果之间微小的差别表明,投影不是解决问题的关键所在,所以后面的实验不使用C而是使用B,以节省内存和运行时间,减少模型的大小,而identity shortcut才是保证模型复杂度不增加的关键。
Bottleneck架构
为了减少模型的参数量从而节省训练时间,作者将原来设计的二层残差块(下图左边)修改成了三层残差块(下图右边),捷径还是使用identity shortcut图来自原论文:
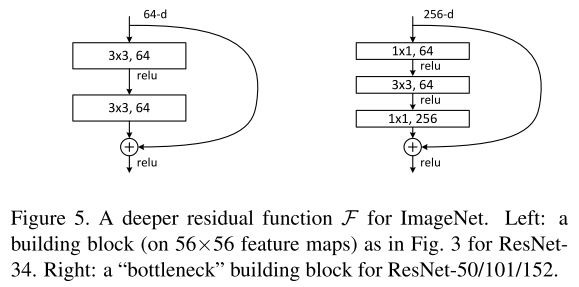
修改结构之后,我们发现参数量改变了,对于左边结构的参数量:
1 | 3*3*64*64 + 3*3*64*64 = 73728 |
右边结构的参数量:
1 | 1*1*256*64 + 3*3*64*64 + 1*1*64*256 = 69632 |
参数量有所减少。bottleneck中的残差块三层分别为:,,的卷积层,其中卷积层负责将特征的维度减少然后增加,这样设计其实起到了编码的作用,而且可以减少参数量, 因为首先减少通道维度,就可以减少的卷积核数量,这样节省下来的参数量是很多的。
identity shortcut相对于bottleneck是非常重要的,首先它不会徒增参数量,如果将bottleneck的架构中的identity shortcut换成projection shortcut,那么时间复杂度和模型的大小会加倍,因为shortcut(捷径)和两个高维向量直接相关联。
在将2层残差块结构换成3层残差块结构之后,模型的网络层总数就变成了50层(ResNet-50, 如表1所示)。然后增加残差块就构建了ResNet-101和ResNet-152,两种网络结构的复杂度仍然比VGG-16/19低。
既然使用本文提出的架构增加网络的深度可以提升精度,那么在网络深度极深的情况下会怎么样呢?
极深网络下的研究
为了探究基于bottleneck结构的极深情况下网络的表现情况,作者直接使用CIFAR-10数据集,使用的网络结构类似于34层的plain net和resnet。输入图像大小为,并将逐个像素减去均值。使用一系列卷积层堆叠的6n层网络在3种不同大小的特征图下进行运算,通过设置不同的n值从而实现调节整个网络的层数。当设置n=200时,网络层数高达1202层,如此夸张深度的网络在训练过程中仍然可以不断降低训练误差,但是测试误差有略微升高,作者分析这是过拟合造成的。
其他视觉任务上的应用
除了图像分类之外,作者还将ResNet运用在其他视觉领域。如Object detection, ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation,而且都取得不错的结果。所以一个通用的方法往往在多个任务上都可以取得令人满意的效果。
为什么ResNet有效?
从反向传播的角度来分析,我们对一个函数求偏导的时候,有如下的链式法则:
随着层数的加深,在不断累乘下,值会越来越小。这也解释了,为什么随着网络的层数加深,梯度值会越来越小,导致模型性能降低。那么如何分析ResNet反向传播时模型在网络较深的情况下仍然可以训练得动呢?我们假设在一个残差块的输入为,多个残差块所起到的映射作用为,那么这个残差块的输出为,如下图所示:
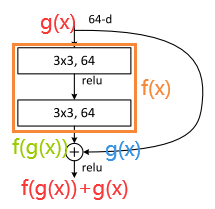
反向传播求导的时候就变成了:
从公式上可以看见,添加了一项,是残差块的输入项,也是前一层网络的输出项,这一项始终保留着前面训练的结果,如果经过残差块里的几层网络之后,梯度值降低了,那么最后反向传播的时候仍然可以使用前一层结果()的梯度值来进行训练,从而缓解了梯度消失的情况。
论文写作技巧
一篇论文中最重要的部分是Abstract 和Introduction。Introduction是Abstract的扩充版本,也是比较完整的对整个工作的描述,要让读者读完这两个部分就懂了文章主要内容与核心思想。
在文章的Abstract中第一句话就提出问题:
Deeper neural networks are more difficult to train.
第二句话提出文章关心的重点,提出什么方法,有如何的效果:
We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously.
然后是我们如何做的,不需要细说:
We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions.
然后是我们做了什么实验,这里简单的提一下,然后说实验的结果。如果有新的架构或者实验有比较明显的特点,要在Abstract中提一下,这样可以更好地吸引读者继续读下去。比如本文提到使用了非常深的网络152层,比VGG多8倍,但是最终的复杂度却更小;再比如还使用了1000层的网络在CIFAR-10中训练。
接着应该是文章的结论,但是本文没有结论,因为文章发布在CVPR上,要求每篇文章的正文不能超过8页。
在论文的第一页右上角有一张图,也是一般论文的布局方法,将最好看的一张图放在这里,图可以是结论、分析数据等,可以吸引读者。
在文章的Introduction部分,作者通过不断的提出问题,介绍前人如何解决的,然后介绍目前遇到的瓶颈,最后就将读者牵引至本文所需要解决的问题中。
在Related work中,主要介绍本文的核心工作所使用到的方法,前人有何种研究,效果如何,与本文的方法简单做一下比较。介绍完这一节,就开始本文的相关工作了。

