在学习《动手学习深度学习》教程的时候对于多项式拟合这一节有一些需要记录的内容.
原教程见这里:https://zh-v2.d2l.ai/chapter_multilayer-perceptrons/underfit-overfit.html
数据的生成与处理
给定一条数据x,我们使用一下的三阶多项式来生成训练和测试数据的标签:
y=5+1.2x−3.42!x2+5.63!x3+ϵ where ϵ∼N(0,0.12)
噪声项ϵ服从均值为0且标准差为0.1的正态分布,在优化的过程中,我们通常希望避免非常大的梯度值或损失值。这就是将特征从xi调整为i!xi,这样可以避免很大的i带来的特别大的指数值。我们将为训练集和测试集各生成100个样本。
1
2
3
4
| max_degree = 20
n_train, n_test = 100, 100
true_w = np.zeros(max_degree)
true_w[0: 4] = np.array([5, 1.2, -3.4, 5.6])
|
因为我们后面需要实现的效果是,通过修改传入的数值来改变多项式的项数,但是最大我们限制为20项。
1
2
3
4
5
| features = np.random.normal(size=(n_train + n_test, 1))
np.random.shuffle(features)
poly_features = np.power(features, np.arange(max_degree).reshape(1, -1))
|
我们随机生成一个维度为(200, 1)的矩阵features,对于这个矩阵中的每一个元素都可以作为一个输入的x来代入上述三阶多项式获得最终的数据标签,所以接下来我们需要构造上述关于x的三阶多项式。
输入np.power函数里的两个参数的形状分别为(200, 1)和(20, 1),最终得到的poly_features形状为(200, 20),是如何操作的呢?我们举个例子:
1
2
3
4
| fea = np.array([[2], [3], [5], [9]])
t = np.arange(3).reshape(1, -1)
answer = np.power(fea, t)
print(answer)
|
也就是将每一个在fea里的元素都经过0次方、1次方、2次方,然后输出,得到的结果为:
1
2
3
4
| array([[ 1, 2, 4],
[ 1, 3, 9],
[ 1, 5, 25],
[ 1, 9, 81]], dtype=int32)
|
这样我们就容易理解为什么poly_features最终的形状会变成(200, 20),其中的200指的是200个输入的x,20指的是对每一个x都经过0,1,2,...,19次幂计算的结果,所以每一列都是对不同的x进行同一种幂指数的计算,然后我们对每一列除以相同的阶乘:
1
2
| for i in range(max_degree):
poly_features[:, i] /= math.gamma(i + 1)
|
最后我们还需要将权重(系数)和x相乘:
1
2
|
labels = np.dot(poly_features, true_w)
|
其中,poly_features.shape=(200, 20),true_w.shape=(20, )。
训练、评估:
教程中剩下来的内容好理解,就是常规的训练、评估的过程,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| def train(train_features, test_features, train_labels, test_labels, num_epochs=400):
loss = nn.MSELoss()
input_shape = train_features.shape[-1]
net = nn.Sequential(
nn.Linear(input_shape, 1, bias=False)
)
batch_size = min(10, train_labels.shape[0])
train_iter = d2l.load_array((train_features, train_labels.reshape(-1, 1)), batch_size)
test_iter = d2l.load_array((test_features, test_labels.reshape(-1, 1)), batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=0.01)
animator = d2l.Animator(xlabel='epoch', ylabel='loss', yscale='log',
xlim=[1, num_epochs], ylim=[1e-3, 1e2],
legend=['train', 'test'])
for epoch in range(num_epochs):
d2l.train_epoch_ch3(net, train_iter, loss, trainer)
if epoch == 0 or (epoch + 1) % 20 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('weight:', net[0].weight.data.numpy())
|
拟合、欠拟合、过拟合:
欠拟合是指模型无法继续减少训练误差。过拟合是指训练误差远小于验证误差。
需要注意的是,教程通过简单的修改输入数据的特征维数就可以实现不同项数的多项式拟合,为什么?
比如教程中通过如下代码实现较为接近的拟合结果:
1
| train(poly_features[: n_train, : 4], poly_features[n_train: , : 4], labels[: n_train], labels[n_train: ])
|
输出:weight: [[ 4.9948716 1.1728584 -3.4092236 5.648857 ]]
拟合结果如下:
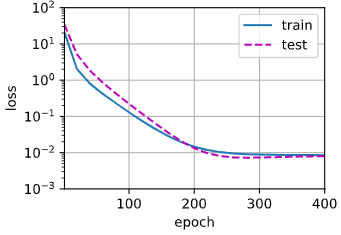
通过修改4->2为欠拟合:
1
2
3
|
train(poly_features[:n_train, :2], poly_features[n_train:, :2],
labels[:n_train], labels[n_train:])
|
输出:weight: [[3.4502087 3.227234 ]]
拟合结果如下:
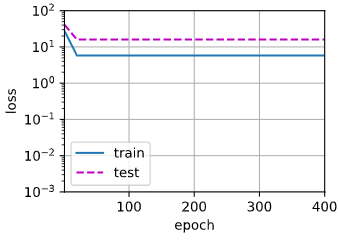
将所有的特征输入为过拟合:
1
2
3
|
train(poly_features[:n_train, :], poly_features[n_train:, :],
labels[:n_train], labels[n_train:], num_epochs=1500)
|
输出:weight: [[ 4.9890423 1.2504098 -3.3738236 5.1632943 -0.15780173 1.4773566 0.35267243 0.36623996 0.11147966 0.18180016 -0.12584884 -0.19590111 0.18171196 0.10465395 -0.00926672 0.1231349 0.06259698 -0.18644147 -0.06582949 -0.05257604]]
拟合结果如下:
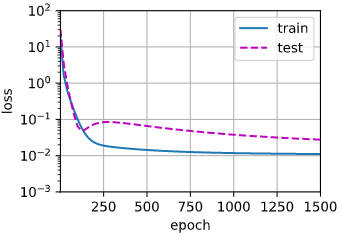
首先,项数越多,就越容易过拟合,这个容易理解,为什么呢?因为项数多,每一项前面的系数都作为参数需要学习,参数量大,在这种情况下,没有足够的数据用于学到高阶系数应该具有接近于零的值。因此,这个过于复杂的模型会轻易受到训练数据中噪声的影响。虽然训练损失可以有效地降低,但测试损失仍然很高。结果表明,复杂模型对数据造成了过拟合。
程序会根据输入特征的维数来构建神经网络,假设输入的特征维度为:(200, n),其中200表示样本的数量,在本案例中表示不同的x的值的数量,n表示关于x的多项式的项数,然后根据这个维度来构建全连接层,这个全连接层的形状为(n, 1),参数的数量为n * 1 = n,这就解释了为什么输入的特征维度就决定了参数数量,也就是多项式的项数。所以从中我们也受到启发,即在输入数据的特征过多的时候,容易造成过拟合,所以限制特征的数量是缓解过拟合的一种常用技术。
我们还可以发现,深度学习是一个全局调试所有的参数,从而使得所有的参数共同作用时可以满足大部分任务的过程。我们可以设想输入的是一张图片,为了好理解,假设都是全连接层,那么对于图像每一个像素都添加一个权重参数,然后全局调整这些参数的值从而使得网络能最大限度的精准分类图像的结果。
绘制训练损失和模型复杂度(多项式的阶数)的关系图
我们每一次设定不同的多项式阶数(输入X的特征维度)都会经过num_epoch轮迭代,每一轮中又会经过N/batch_size次迭代,所以一共经过num_epoch*N/batch_size次迭代之后,我们就认为当前设定的多项式阶数训练结束了,就需要将我们的训练损失以及当前的阶数绘画出来。基于这个思路我们修改代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| def train(train_features, test_features, train_labels, test_labels, num_epochs=400):
loss = nn.MSELoss()
input_shape = train_features.shape[-1]
net = nn.Sequential(
nn.Linear(input_shape, 1, bias=False)
)
batch_size = min(10, train_labels.shape[0])
train_iter = d2l.load_array((train_features, train_labels.reshape(-1, 1)), batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=0.01)
for _ in range(num_epochs):
train_loss, train_acc = d2l.train_epoch_ch3(net, train_iter, loss, trainer)
return train_loss, train_acc
|
1
2
3
4
5
6
| animator = d2l.Animator(xlabel='degree', ylabel='loss', yscale='log',
xlim=[1, 20], ylim=[1e-3, 1e2],
legend=['train_loss'])
for i in range(2, 21):
train_loss, train_acc = train(poly_features[: n_train, : i], poly_features[n_train: , : i], labels[: n_train], labels[n_train: ])
animator.add(i - 1, train_loss)
|
输出图像如下:
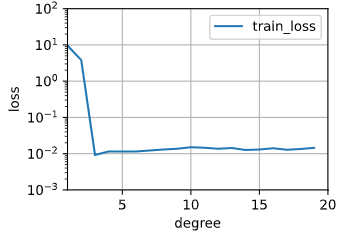
从训练损失中可以看到,当阶数在3左右的时候训练损失是最小的,之后随着阶数的增加,训练损失不会下降反而微量上升。
绘制训练损失和数据量的关系图
从训练损失和阶数的关系图来看,当阶数为3的时候训练损失是最小的,我们就固定模型的阶数为3,然后成倍的增加数据量看看结果如何,同样,我们修改代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| def train(train_features, train_labels, num_epochs=400):
loss = nn.MSELoss()
input_shape = train_features.shape[-1]
net = nn.Sequential(
nn.Linear(input_shape, 1, bias=False)
)
batch_size = min(10, train_labels.shape[0])
train_iter = d2l.load_array((train_features, train_labels.reshape(-1, 1)), batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=0.01)
for _ in range(num_epochs):
train_loss, train_acc = d2l.train_epoch_ch3(net, train_iter, loss, trainer)
return train_loss, train_acc
def generate_features(n):
max_degree = 20
true_w = np.zeros(max_degree)
true_w[0: 4] = np.array([5, 1.2, -3.4, 5.6])
features = np.random.normal(size=(200 * n, 1))
np.random.shuffle(features)
poly_features = np.power(features, np.arange(max_degree).reshape(1, -1))
for i in range(max_degree):
poly_features[:, i] /= math.gamma(i + 1)
labels = np.dot(poly_features, true_w)
labels += np.random.normal(scale=0.1, size=labels.shape)
return poly_features, labels
|
1
2
3
4
5
6
7
8
9
10
11
12
| n_train = 200
animator = d2l.Animator(xlabel='data', ylabel='loss', yscale='log',
xlim=[200, 2000], ylim=[6e-3, 1e-1],
legend=['train_loss'])
poly_features, labels = generate_features(10)
poly_features = torch.tensor(poly_features, dtype=torch.float32)
labels = torch.tensor(labels, dtype=torch.float32)
for i in range(1, 11):
train_loss, train_acc = train(poly_features[: n_train * i, : 4], labels[: n_train * i])
print(train_loss)
animator.add(i * n_train, train_loss)
|
得到的图像如下:
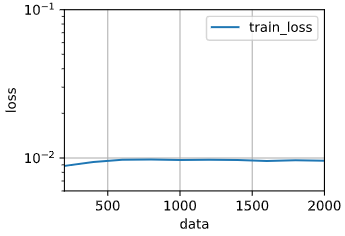
从图中观察到从数据量200往后越来越多之后,训练误差也在变高,可能是数据量变化的幅度太大,观察的结果不够明显。
如果不对多项式特征xi进行标准化(1/i!),会怎样?
将这部分代码注释掉:
1
2
| for i in range(max_degree):
poly_features[:, i] /= math.gamma(i + 1)
|
进行训练得到如下的结果:
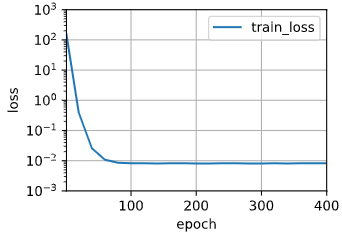
按照正常情况应该会造成梯度或者损失过大的,但是这里没有出现那种情况。如果我不断的增加多项式的项数进行训练呢?结果如下:
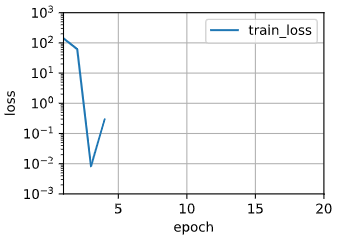
之后没画出来是因为损失为NaN,一般是梯度爆炸造成的,解决梯度爆炸可以使用如下方式解决:
- 对训练集的输出(label)使用分为标准化,抑制过大的输出;
- 为模型增加正则化;
- 减少模型的规模;
- 增大batch_size大小。
Reference:
https://blog.csdn.net/xovee/article/details/92762035

