Why federated learning?
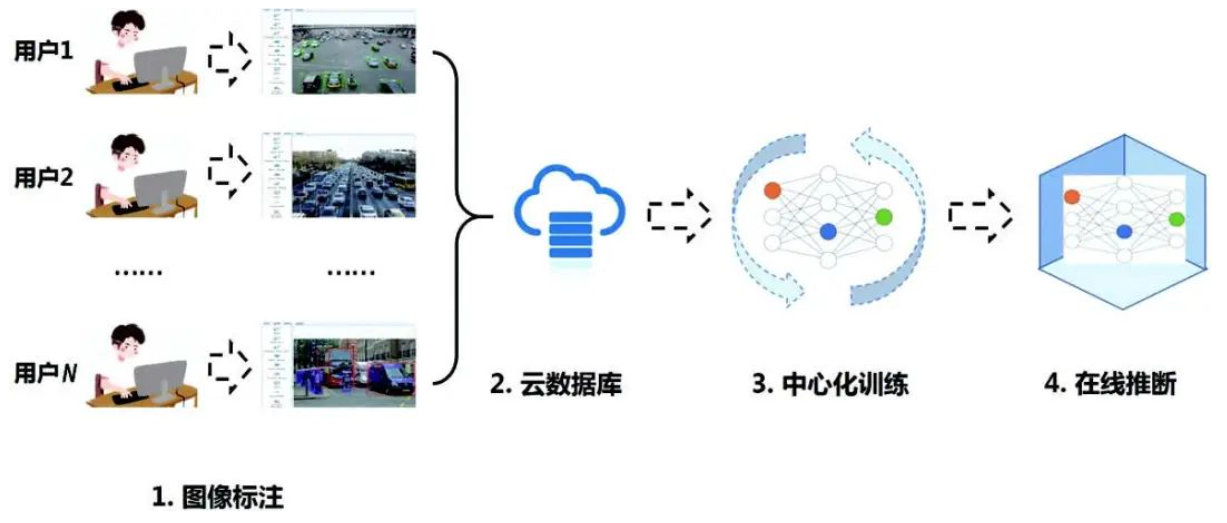
现阶段深度学习大多是集中式训练。多个客户端将数据标注并上传至云服务器,服务器集中训练模型,最后将训练的模型部署到客户端。如下图所示(图来自:https://blog.csdn.net/lgzlgz3102/article/details/117433511)。这种中心化的训练模式面临许多困难,数据隐私方面:多个客户采集的数据不愿分享的情况,数据的割裂导致只能利用本地的数据进行单点建模,模型效果自然明显下降;模型更新方面:传统的处理方式需要将数据集中上传到中心数据库,进行统一的数据处理和模型训练,然后进行模型的评估和部署,由于各个数据院之间的网络性能和设备性能的差异,导致数据同步不一致,整个流程会持续较长的时间,无法满足实时响应的场景。
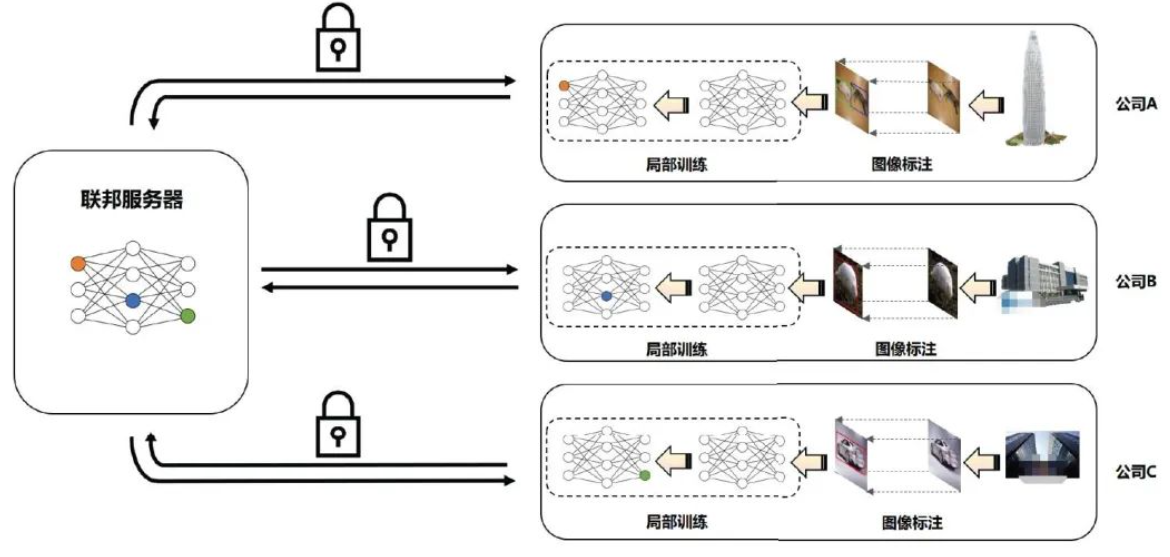
The work of federated learning?
各个用户之间,数据不可见,所以各自利用各自的数据进行训练,然后将模型的参数上传至服务器,服务器整合并将更新的模型参数下发给其他的所有节点,再次进行上述步骤,直至拟合。
联邦学习论文的研究侧重点统计

Challenges
客户端的optimizer和server端的optimizer是否能互相配合使用,从而让效果更好;
不同的客户端的计算能力不同,所以设定迭代次数k会导致互相等待,能否根据不同的机器设置不同的迭代次数k,从而让效果较优。这就是k异构下如何优化的问题。
如果有些客户端是手机,需要训练的是ResNet模型,如果直接用手机来训练显然不合适,那么如何解决这个问题。
FedML:A Research Library and Benchmark for Federated Machine Learning
FedCV: A Federated Learning Framework for Diverse Computer Vision Tasks

