numpy广播在语义分割上的妙用
假设输入的图像大小为:536x559:

我们还有如下的标签文件:

不同颜色和标签的含义如下:
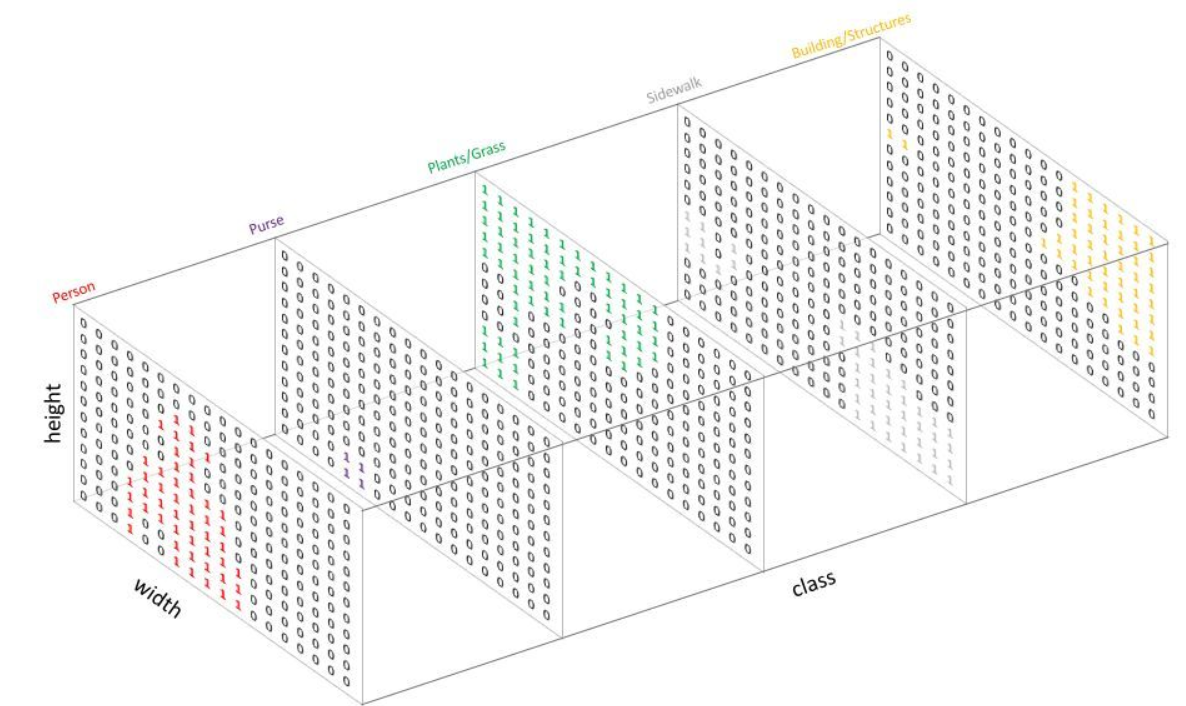
接下来需要对标签文件中的不同物体颜色块进行分离,即达到如下的效果:
为了方便输出,我们使用一个小一点的张量来测试。首先读取mask文件:
1 | mask = np.random.randint(0, 4, (5, 3)) |
使用np.unique()函数去重并将数据排序:
1 | obj_ids = np.unique(mask) |
扩展obj_ids的维度,以便实现广播:
1 | print(obj_ids[:, None, None]) |
开始分离物体颜色块(需要注意的是,0一般为背景,需要去掉,这里保留是为了增强表达效果,如需去掉,则obj_ids = obj_ids[1: ] ):
1 | masks = mask == obj[:, None, None] |
最后输出的masks的形状表示4个物体(0, 1, 2, 3)各自提取出来的掩膜形状为(5, 3)。
一开始最难以理解的是维度扩充那里,即:
1 | obj_ids[:, None, None] |
这里扩充是为了满足广播的条件,一开始的obj_ids维度为一维,我们需要将obj_ids中的每一个元素都与mask中的每一个元素进行比较一番(当然最简单的方法可以使用循环实现,但是效率低下),为了实现并行处理,需要将(0,1,2,3)中的每一个元素扩充为二维的形式,即分别为:
1 | [[[0]] |
然后在进行比较的过程中就可以自动使用广播机制来进行加速计算:
1 | [[0, 0, 0], |

