CPU的资源有限,任务处理速度与线程的个数不是线性相关,过多的线程反而会导致CPU的频繁切换,处理性能下降。所以,线程池的大小一般都是综合考虑要处理任务的特点和硬件环境来实现设置的。
一般有两种处理策略。第一种是非阻塞的处理方式,直接拒绝任务请求;另一种是阻塞的处理方式,将请求排队,等到有空闲线程时,取出排队的请求继续处理。那么如何处理排队的请求呢?
我们希望公平地处理每个排队的请求,先进者先服务,所以队列这种数据结构很适合来存储排队请求。队列有基于链表和基于数组这两种实现方式。这两种实现方式对于排队请求又有什么区别呢?
基于链表的实现方式,可以实现一个支持无限排队的无界队列(unbounded queue),但是可能会导致过多的请求排队等待,请求处理的响应时间过长。所以,针对响应时间比较敏感的系统,基于链表实现的无限排队的线程池是不合适的。
而基于数组实现的有界队列(bounded queue),队列的大小有限,所以线程池中排队的请求超过队列大小时,接下来的请求就会被拒绝,这种方式对响应时间敏感的系统来说,就相对更加合理。这种方式的不好的地方就是:如果某一时刻任务太多,会造成任务的丢失。不过,设置一个合理的队列大小,也是非常有讲究的。队列太大导致等待的请求太多,请求得不到及时的响应,用户体验就会下降;队列太小会导致无法充分利用系统资源、发挥最大性能。当队列阻塞时,队列所在的服务端可以发给客户端一个 500 或者 503 的状态码,然后客户端收到此状态码后可以一直尝试重发请求,直至请求被处理。当然这并不是最高效的处理方式。
除了前面讲到队列应用在线程池请求排队的场景之外,队列可以应用在任何有限资源池中,用于排队请求,比如数据库连接池等。
实际上,对于大部分资源有限的场景,当没有空闲资源时,基本上都可以通过“队列”这种数据结构来实现请求排队。
具有某些额外特性的队列
循环队列
阻塞队列
并发队列
高性能队列 Disruptor、Linux 环形缓存,都用到了循环并发队列;Java concurrent 并发包利用 ArrayBlockingQueue 来实现公平锁。
顺序队列和链式队列
使用数组实现的队列是顺序队列,顺序队列的删除操作都是删除队列中的第一个元素,如果每一次删除都需要搬移数据的话,时间复杂度将变成,所以我们可以等到无法入队之后一起搬移从而得到优化。
具体而言,实现顺序队列的时候我们定义了两个指针:tail指针和head指针,如果删除了元素,head指针加一;如果插入了元素,tail指针加一,一旦tail指针移动到了数组的最后,再次有新的元素入队时,我们就将整体head-tail之间的数据搬移到数组中以0索引开头的位置。
这种实现思路,出队操作的时间复杂度仍然为,但是入队操作就需要具体分析一下了,因为入队操作可能会导致整体数据的移动。假设预先定义的数组长度为n,那么在前n次入队操作都不会导致数据的搬移,因为即便是有出队,也只是移动队头指针head,而队尾指针会随着入队的数据增加而右移。当第n+1次入队操作的时候,需要首先将所有的数据移动格,即一共移动格,借助王争老师的手绘图表示如下(强烈建议购买王争老师在极客时间的数据结构与算法之美原作):
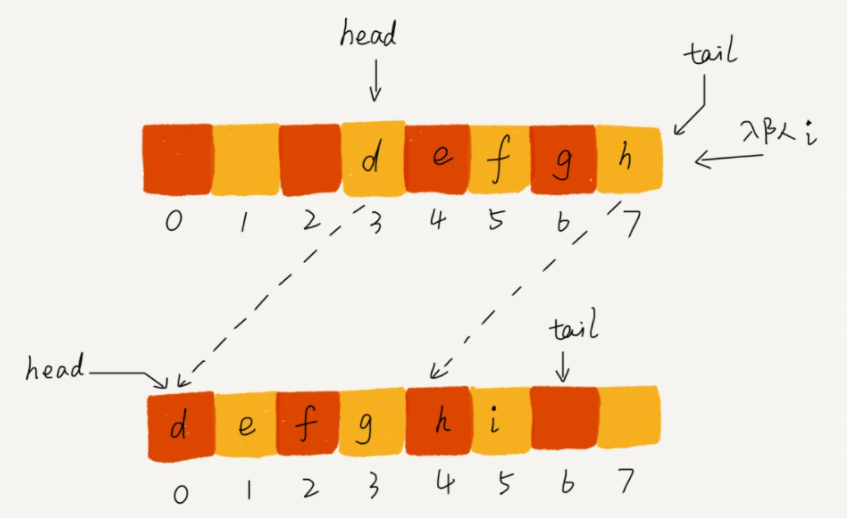
对于这种情况下的时间复杂度可以使用摊还分析法来分析,当时,执行:
1 | for (int i = head; i < size; i++) { |
移动一个元素的时间复杂度为,那么将所有的移动时间均摊到每一个节点的话,总体的时间复杂度就是。
循环队列
在上面讲到的顺序队列中,我们出队之后不马上搬移数据,而是等到队尾指针到达数组最后的时候才移动,这样可以减少很多移动数据而花费的时间,但是最后还是移动了,那么我们能否避免移动数据呢?
答案是可以的,我们可以使用循环队列的实现方式来避免数据的移动。在顺序队列中,判断队列的状态代码如下所示:
1 | // 判断队列空 |
到了循环队列,我们判断队列的状态代码如下所示:
1 | // 判断队列空 |
判断队列空容易理解,但是判断队列满为什么需要模运算呢?我们考虑两种情况:
-
这种情况如果再加一个就和重合。
-
这种情况下,如果的索引值为,而,此时其实队列已经满了,但是就超过了数组的范围,而我们需要的是和对头指针比较,而且两者刚好相差了一个队列的长度,这个时候就用模运算来实现。
其实想到这里我们会发现,我们可以用判断语句来代替模运算,这样容易理解,但是代码工程量大的时候就会降低效率,所以与其说是可以用判断语句来代替模运算,不如说模运算可以用来优化这里的判断语句,代码优化需要从编程的点点滴滴做起。
基于数组的循环队列比链式队列应用更加广泛,原因:
-
CAS(Compare And Swap)比较并替换,是线程并发运行时用到的一种技术,基于数组可以比较原来的head/tail索引,实现线程安全;
-
基于数组的循环队列,利用CAS(Compare And Swap)原子操作. 可以实现一个非常高效的
并发队列; -
数据操作O(1)复杂度,不用搬移数据。
阻塞队列和并发队列
阻塞队列其实就是在队列基础上增加了阻塞操作。简单来说,就是在队列为空的时候,从队头取数据会被阻塞。因为此时还没有数据可取,直到队列中有了数据才能返回;如果队列已经满了,那么插入数据的操作就会被阻塞,直到队列中有空闲位置后再插入数据,然后再返回。这一功能是否与操作系统的临界区管理中的PV操作似曾相识呢?这其实可以实现一个“生产者-消费者”模型。
这种基于阻塞队列实现的“生产者 - 消费者模型”,可以有效地协调生产和消费的速度。当“生产者”生产数据的速度过快,“消费者”来不及消费时,存储数据的队列很快就会满了。这个时候,生产者就阻塞等待,直到“消费者”消费了数据,“生产者”才会被唤醒继续“生产”。
基于阻塞队列,我们还可以通过协调“生产者”和“消费者”的个数,来提高数据的处理效率。比如前面的例子,我们可以多配置几个“消费者”,来应对一个“生产者”。
在多线程情况下,会有多个线程同时操作队列,这个时候就会存在线程安全问题,那如何实现一个线程安全的队列呢?
阻塞队列可能多个数据同时出队列,线程不安全,可以对入队或者出队加上锁,这样线程安全的队列,叫做并发队列。最简单直接的实现方式是直接在 enqueue()、dequeue() 方法上加锁,但是锁粒度大并发度会比较低,同一时刻仅允许一个存或者取操作。如何实现一个高效的并发队列:
- 基于数组的循环队列(避免数据搬移) ;
- CAS原子操作(避免真正的去OS底层申请锁资源)。
可以参考这篇文章来了解一下CAS:
https://zhuanlan.zhihu.com/p/85727736
思考
-
除了线程池这种池结构会用到队列排队请求,还有哪些类似的池结构或者场景中会用到队列的排队请求呢?
临界区管理的PV操作;
先进先出页面替换算法;
作业调度中的作业后备队列;
作业调度、进程调度算法(如先来先服务算法、时间片轮转算法、多级反馈队列算法等)中的就绪队列的实现;
分布式应用中的消息队列,如 kafka 也是一种队列;
考虑使用CAS实现无锁队列,则在入队前,获取tail位置,入队时比较tail是否发生变化,如果否,则允许入队,反之,本次入队失败。出队则是获取head位置,进行CAS;
-
关于如何实现无锁并发队列,网上有非常多的讨论。如何看待?
可以使用 CAS + 数组的方式实现.
-
在循环队列中,判断队列是否满,可以判断是否成立,还有一种说法是创建一个变量来存放当前队列的非空余部分的大小,每一次将其与size比较即可,如何看待这种思路?
创建一个额外的变量,需要在并行开发的时候进行维护,从这个角度来讲,前者更优。

